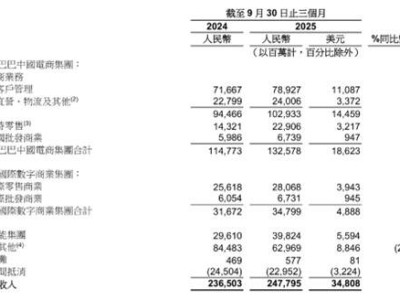
可靈AI近日通過官方渠道正式宣布,其自主研發的全球首款統一多模態視頻生成模型——可靈視頻O1已面向全體用戶開放使用。這一突破性技術通過整合多模態交互能力,重新定義了視頻創作的邊界。
據技術團隊介紹,可靈O1模型的核心創新在于構建了新一代生成式架構底座。該架構突破了傳統功能模塊的割裂狀態,通過引入多模態視覺語言(MVL)交互框架,實現了文本、圖像、視頻等多元輸入在單一操作界面的無縫融合。結合思維鏈(Chain-of-thought)技術,模型展現出對復雜場景的深度理解能力,能夠基于常識進行事件推演和邏輯推導。
官方演示顯示,新上線的創作平臺采用對話式交互設計,用戶僅需通過自然語言描述需求,即可調用系統內置的百萬級素材庫。從人物表情到光影效果,每個細節均可通過多輪對話實現精準調控。特別值得關注的是,模型對主體特征的捕捉能力達到行業領先水平——即便在鏡頭快速切換或視角劇烈變化時,仍能保持主體形態、色彩、紋理的高度一致性。
在多主體交互場景中,該模型展現出獨特的創作優勢。用戶可自由組合多個獨立元素,系統會自動分析各主體間的空間關系與動作邏輯,生成符合物理規律的動態畫面。這種技術突破為復雜敘事視頻的自動化生成提供了可能,在影視制作、廣告營銷等領域具有廣泛應用前景。