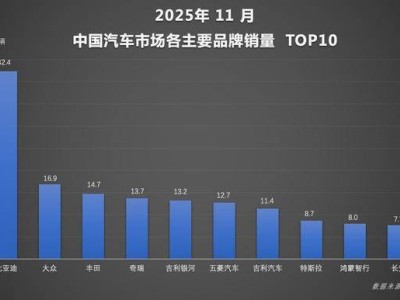
在生成式人工智能技術席卷編程領域的當下,圍繞大語言模型能否真正提升開發效率的爭議持續發酵。科技觀察者發現,盡管AI代碼生成工具為非專業人士打開了應用開發的大門,但其實際效能仍存在顯著爭議。部分開發者通過AI工具成功創建了基礎應用程序,但專業社區普遍認為,這類工具生成的代碼在質量與實用性層面存在明顯短板。
開源桌面環境GNOME近日更新擴展開發規范,明確禁止提交由AI獨立生成的代碼。項目維護團隊在聲明中強調,雖然不排斥開發者將AI作為輔助學習或開發工具,但要求所有代碼提交必須經過人工審查與解釋。審核標準特別指出,包含大量冗余代碼、API使用錯誤、風格混亂或殘留AI提示詞注釋的擴展將直接被拒。
該決策背后折射出開源社區對代碼質量的嚴苛要求。維護團隊成員透露,過去半年接收的AI生成代碼中,超過60%存在基礎邏輯錯誤,部分擴展甚至包含虛構的函數調用。這種低質量代碼不僅增加審核負擔,更可能通過模塊復用機制污染整個代碼生態系統。一位資深開發者形象地比喻:"這類代碼就像數字牛皮癬,一旦進入公共倉庫就會快速擴散。"
從項目管理視角分析,GNOME的決策具有雙重考量。一方面要求開發者對代碼負責,避免將技術債務轉嫁給維護團隊;另一方面通過強制注釋規范,確保代碼庫的可維護性。這種做法在開源領域引發連鎖反應,多個知名項目開始重新評估AI生成代碼的準入標準,部分社區甚至考慮建立專門的AI代碼審查通道。
技術倫理專家指出,這場爭議暴露出AI工具在專業領域的局限性。當前生成式模型擅長模仿代碼模式,但缺乏對系統架構、性能優化等深層邏輯的理解。某AI公司工程師坦言:"我們的模型能寫出語法正確的代碼,但無法判斷哪種實現方式更符合項目長期需求。"這種技術短板在復雜系統開發中尤為明顯,解釋了為何專業社區對AI代碼持謹慎態度。