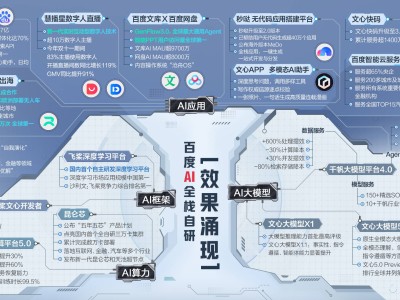
近日,北京迎來了一場聚焦人工智能前沿成果的盛會——“2025百度十大科技前沿發明”發布會。此次發布的十項發明覆蓋大模型、深度學習框架、AI算力、智能體、AI搜索、數字人、無人駕駛等核心領域,不僅展現了百度在AI底層技術的突破性進展,更勾勒出AI應用從技術積累向場景落地的關鍵路徑,為行業構建起覆蓋“算力-框架-模型-場景”的全棧技術圖譜。
在基礎模型層面,新一代文心大模型的核心技術“自回歸統一建模的原生多模態大模型”成為焦點。該技術首次實現語言、圖像、視頻、音頻的統一建模框架,支持任意模態的理解與生成,并構建了面向大模型的獎勵系統。通過多環境多任務場景的強化學習,新一代模型在各模態任務上較上一代顯著提升,并發能力增強且響應時間縮短,為復雜場景應用提供了技術支撐。例如,在醫療影像分析中,模型可同步處理CT影像與患者語音描述,生成結構化診斷報告;在智能教育場景中,能根據學生語音提問自動生成圖文并茂的解答內容。
針對大模型訓練的穩定性難題,“大模型訓練全流程高效容錯技術”提出了創新解決方案。通過構建軟硬件故障自動召回定位恢復體系,該技術攻克了集群訓練中故障定位與召回恢復兩大核心挑戰。其零損失訓練快照機制可在故障發生時瞬間保存訓練狀態,結合全場景故障定位方法,使萬卡集群任務的訓練有效率超過98%,資源利用效率顯著提升。目前,該技術已應用于文心大模型系列訓練,支撐起每日數萬次的高強度計算需求。
在數字人領域,“劇本驅動的高說服力數字人技術”推動了行業進入普惠化階段。該技術整合可控視頻生成、超擬真唇形驅動、劇本智能創作與AI大腦自主決策四大能力,突破了大表情/大動作生成、音容話一致、人-物-場交互等業界難題。以羅永浩數字人直播間為例,雙數字人互動模式實現單場GMV超5500萬元,后驗數據全面超越真人主播。這項技術不僅降低了數字人制作成本,更通過AI大腦賦予其自主決策能力,可靈活調度助播、場控等角色,形成“一人即團隊”的營銷生態。
搜索場景的革新體現在“基于多智能體協同的AI搜索引擎”上。該技術以Master-Planner–Executor-Generator四層智能體體系為底座,模擬人類信息處理的“感知-規劃-執行-生成”全流程。在百度文心助手中,這一技術支撐起復雜問題拆解、富媒體呈現、個性化滿足等核心能力,使日活躍用戶與用戶留存率顯著提升。例如,當用戶搜索“北京周末親子游”時,搜索引擎可自動規劃包含景點、交通、餐飲的完整方案,并生成圖文并茂的行程手冊。
視頻生成領域,“蒸汽機(文心專精)音視頻一體化生成大模型技術”開啟了雙向共創新階段。作為全球首個中文音視頻一體化生成模型,它支持分鐘級多人有聲音視頻生成與交互,通過LatentMultiModalPlanner技術重構生成邏輯,實現視頻全流程有聲一體化。在影視創作場景中,該技術可將制作成本降低70%,同時提供大師級運鏡控制。對外賦能方面,其長視頻實時交互生成能力已應用于商業內容生產、搜索妙筆等業務,推動百度AI視頻生態繁榮。
在自動駕駛領域,“兼容端到端軌跡方案的橫縱聯合控制技術”實現了技術躍遷。基于車輛橫縱耦合動力學,該技術設計的線性時變模型預測控制器,使橫向晃動幅度優化70%,彎道橫向抽動問題完全消除。目前,搭載該技術的蘿卜快跑自動駕駛車輛已駛入香港、迪拜等16座城市,累計提供超1400萬次服務,安全行駛里程突破2億公里,其擬人化控制水平接近經驗豐富的駕駛員。
其他技術同樣亮點紛呈:“從芯片到集群的跨層級訓推一體AI基建系統性技術”構建起完備的AI基礎設施體系,使XPULink帶寬提升8倍,網絡時延壓至4微秒;“信息流端到端內容理解與序列生成技術”突破推薦系統局限,實現多模態內容理解與個性化生成;“飛槳科學計算高效求解技術”將微分方程求解速度提升2-4個數量級,加速科學計算領域創新;“基于智能體的自進化應用生成技術”則通過三重自進化學習架構,使應用開發成本從傳統模式的大約4人周、2萬元縮減到小于1小時、低于50元,純無代碼生成應用已達38萬。