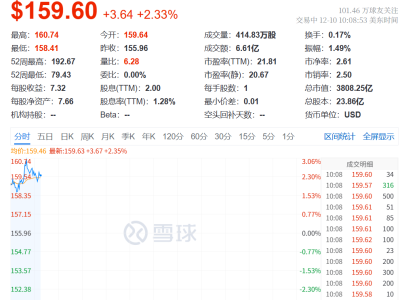
近期,全球AI算力市場正經歷深刻變革,曾經占據絕對主導地位的英偉達面臨前所未有的挑戰。自10月下旬以來,英偉達市值在一個月內縮水超7000億美元,這一劇烈波動折射出行業格局的微妙變化。市場情緒從"英偉達不可替代"轉向"存在替代可能",這種轉變背后是技術路線與商業模式的雙重沖擊。
谷歌TPU的崛起成為這場變革的核心變量。meta計劃從2027年起投入數十億美元采購谷歌TPU的消息,標志著行業頭部玩家開始重新評估技術路線。這款專為深度學習優化的ASIC芯片,通過犧牲通用性換取極致能效比——最新Ironwood版本能效比達到初代產品的30倍,在同等工藝下顯著優于GPU。這種優勢已獲得實踐驗證:OpenAI部分訓練任務、Anthropic下一代大規模訓練平臺均選擇TPU,看中的正是其性能與成本的平衡。
谷歌的商業策略同樣具有顛覆性。其推出的"硬件即服務"模式,通過保留TPU所有權、按使用量分成的方式,大幅降低了合作伙伴的資本性支出。這種"游擊戰式"的市場滲透,使得中小型云廠商無需承擔數十億美元的硬件投資壓力。更值得關注的是,谷歌正在構建從芯片到應用的全棧體系,通過TPU+OCS光互連+Gemini模型+云服務的深度整合,實現系統級優化。這種整合能力在超節點集群構建上尤為突出,第七代TPU已實現9216顆芯片的規模部署,峰值性能達4614TFLOPS。
中國科技企業在這場變革中展現出強勁的追趕勢頭。華為推出的Atlas 960 SuperPoD支持15488張昇騰卡互聯,在關鍵指標上實現全球領先;阿里云磐久128超節點服務器單柜容納128顆AI芯片;百度昆侖芯在百舸5.0中全面啟用超節點并實現量產。國產GPU陣營同樣動作頻頻:曦智科技聯合壁仞、中興推出光互連超節點,燧原云燧ESL實現64卡全帶寬互聯,沐曦曦云C600支持超節點擴展,摩爾線程通過5D分布式技術實現千節點協作。
技術競爭焦點正在發生根本性轉移。單卡性能的重要性持續下降,系統效率、能效比和規模化交付能力成為新的評價標準。超節點集群的快速發展印證了這一趨勢——英偉達提出的概念正被整個行業快速采納,谷歌、華為、阿里等企業均在加速布局。這種轉變背后是AI訓練規模持續擴大的現實需求,當算力需求進入百萬卡級別,系統級優化帶來的效率提升遠超單卡性能改進。
英偉達的應對策略凸顯其戰略定力。公司強調自身仍是"唯一能運行所有人工智能模型的平臺",CUDA生態和通用算力優勢構成核心護城河。但市場觀察家指出,當谷歌能用TPU訓練出最先進模型,當meta將數十億美元訂單投向競爭對手,行業結構已出現細微裂縫。這種裂縫往往預示著更深層次的變革——ASIC在特定任務中的高效率表現,正在特定細分市場對GPU形成實質性威脅。
在這場算力競賽中,性價比成為關鍵制勝因素。SemiAnalysis數據顯示,谷歌TPUv7在成本效率上已對英偉達構成絕對優勢。這種優勢不僅體現在硬件層面,更延伸至整個技術棧的優化。隨著云服務廠商自研ASIC與超節點集群的影響力持續擴大,AI算力競爭正從"芯片之爭"演變為"體系之爭"。對于英偉達而言,既要鞏固現有生態優勢,又要應對新興技術路線的挑戰,這場變革帶來的考驗才剛剛開始。