
英偉達近日正式推出全新開源模型系列Nemotron 3,涵蓋Nano、Super和Ultra三種規格,并同步發布配套技術工具與數據集,旨在為專用智能體AI系統開發提供高性能解決方案。該系列模型通過架構創新與訓練方法突破,在推理效率、長序列處理及多智能體協同等核心場景實現顯著提升。
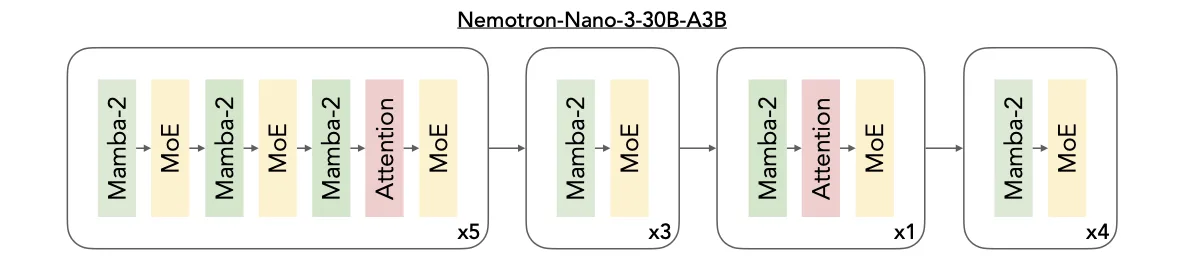
Nemotron 3系列采用差異化定位設計:Nano版本配備300億參數(活躍參數量30億),專為DGX Spark、H100和B200 GPU優化,聚焦高效任務處理,現已投入市場;Super版本擁有1000億參數,側重多智能體協同與高精度推理;Ultra版本參數規模達5000億級,搭載超大推理引擎,可應對最復雜的應用場景。后兩者計劃于2026年上半年發布,通過架構升級進一步擴展基礎能力。
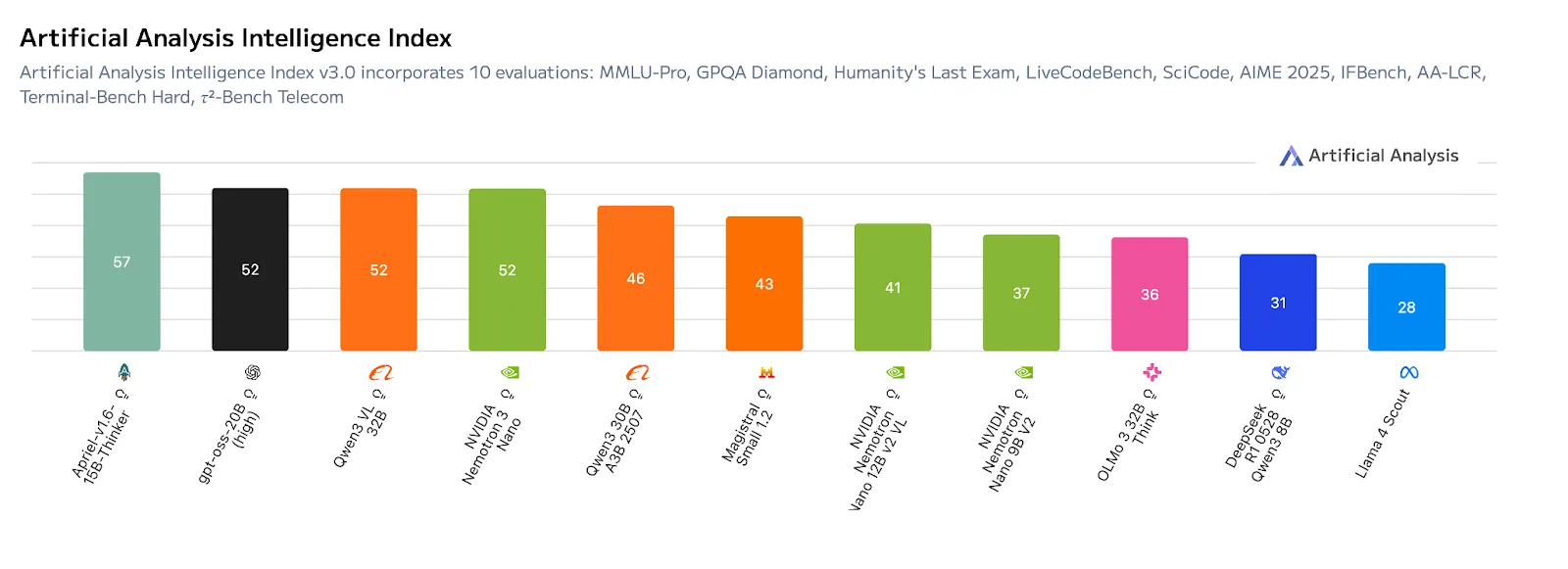
在基準測試中,Nano版本于Artificial Analysis Intelligence Index v3.0中以52分領先同規模模型,其性能優勢源于創新的Mamba-Transformer MoE混合架構。該架構整合三大核心技術:Mamba層以極低內存開銷實現超長序列依賴追蹤,支持百萬級Token處理;Transformer層通過注意力機制精準建模任務邏輯,強化推理能力;MoE路由機制則通過動態調用專家模塊,在控制計算成本的同時提升吞吐效率。這種設計使模型天然適配多智能體并發場景,例如同時生成任務計劃、分析上下文或調用工具執行工作流。
為提升模型實際應用能力,英偉達在開源強化學習平臺NeMo Gym中對Nemotron 3進行后訓練。該平臺模擬真實世界環境,要求模型完成復雜動作序列,如調用API查詢數據、編寫可運行代碼或規劃多階段任務。這種訓練方式有效減少“推理漂移”現象,增強模型處理結構化流程的穩定性,降低將大模型轉化為領域專家的技術門檻。
Nemotron 3的另一突破是支持100萬Token上下文窗口,可完整保存任務背景、歷史記錄與復雜計劃,避免傳統文本切割導致的信息碎片化。這一能力得益于混合架構的低內存開銷特性與MoE機制的按需激活策略,為企業級文檔分析、跨會話協作等場景提供邏輯連貫性保障。
針對Super和Ultra版本,英偉達引入三項進階技術:潛在MoE通過共享潛在表征空間運算,使模型以相同成本調用4倍專家數量,提升對細微語義與復雜推理的處理精度;多Token預測技術允許模型一次生成多個詞,顯著加快長篇邏輯推理與結構化輸出的響應速度;NVFP4訓練格式則通過4位浮點優化,在25萬億Token數據集訓練中實現成本與精度的平衡。
為支持開發者訓練定制模型,英偉達同步開放四大數據集:包含3萬億Token的預訓練集、1300萬樣本的后訓練集3.0、強化學習專用數據集,以及涵蓋近1.1萬條智能體工作流軌跡的安全數據集。結合NeMo Gym、RL、Data Designer等開源工具庫,開發者可完整復現模型開發流程。目前,埃森哲、德勤、甲骨文云基礎設施、西門子等企業已成為Nemotron 3的早期采用者。











