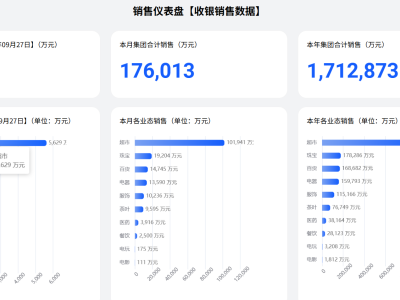
當前,機器人行業正經歷著冰火兩重天的局面。一方面,競技賽事呈現爆發式增長——2025年世界人形機器人運動會吸引16個國家280支隊伍參賽,社交媒體上機器人后空翻、沖咖啡等炫技視頻頻繁刷屏;另一方面,核心技術瓶頸依然突出,某企業人形機器人因末端執行器精度不足,在工業精密作業中的效率甚至低于人工操作。這種理想與現實的割裂,在資本市場上尤為明顯:今年前七個月具身智能領域融資超240億元,但投資者面對數百家機器人公司時,往往陷入“技術含量難判斷、落地潛力看不清”的困境。
行業痛點直指測評體系的缺失。在算法領域,ImageNet、GLUE等基準測試推動了計算機視覺與自然語言處理的跨越式發展,但機器人領域長期缺乏統一標準。現有評估方式呈現兩極化:實驗室測試多在仿真或高度結構化環境中進行,難以反映現實世界的復雜性;企業演示則偏向娛樂化營銷,后空翻機器人與泡咖啡表演雖能吸引眼球,卻無法證明機器人在非結構化環境中的通用能力。這種割裂導致行業信息失真——投資者依賴演示視頻和團隊背景決策,可能使“會表演”的團隊獲得超額融資;企業為追求傳播效果,將研發資源從核心技術轉向炫技功能,形成“劣幣驅逐良幣”的惡性循環。
破局者來自Dexmal原力靈機與HuggingFace的聯合創新。全球首個大規模真機基準測試集RoboChallenge的推出,為行業提供了科學評估的“標尺”。該平臺通過三大創新解決核心痛點:其一,建立統一測評體系,采用UR5、Franka Panda等四類主流機型,在7×24小時真實環境中執行標準化任務,實現跨模型、多任務的公平對比;其二,首創遠程機器人評測模式,研究者無需實體設備即可通過標準化API部署算法,系統提供毫秒級時間戳的RGB圖像與異步處理能力,大幅降低科研門檻;其三,設計精細化評分體系,Table30測試集包含30個覆蓋分揀、倒液體、疊放物體等日常場景的任務,突破傳統二值化評估,引入進度評分機制,精準量化模型代際差異。
技術細節彰顯平臺專業性。首期測試選用配備夾爪的機械臂作為標準化平臺,同步輸出多視角RGB與深度信息,支持VLA算法核心能力評估。遠程評測系統采用無容器化設計,通過HTTP API實現異步處理,智能調度模塊支持多任務并行,確保7×24小時穩定運行。Table30測試集以“科學分類學”為理念,從任務場景、物體屬性等維度構建評估矩陣,官方論文證實其能有效區分不同VLA模型的性能差距——例如Pi05模型在真實測試中成功率與得分顯著領先,而多任務版本表現普遍弱于單任務版本,揭示了當前技術演進的關鍵路徑。
開放性是RoboChallenge的核心競爭力。平臺堅持全面開放原則,向全球研究者免費提供測試服務,公開所有任務數據與中間結果,支持復現實驗與算法優化。官網展示的評測任務列表包含任務名稱、狀態、提交次數等詳細信息,用戶可通過篩選功能快速定位感興趣的內容。這種透明度打破了機器人研發的高門檻,使初創團隊、學術機構甚至在校學生都能在統一標準下參與競爭。目前,平臺已發布擦桌、澆花、開關電器等30個真實場景數據集,所有任務均支持公開訪問,為投資決策、科研創新與產品化提供可靠依據。
從行業影響看,RoboChallenge正重塑機器人技術的發展生態。它迫使企業從“演示優先”轉向“技術優先”,讓投資判斷基于扎實數據而非商業故事;它推動學術界擺脫“重復造輪子”的困境,使突破性成果能快速擴散至全行業;它更降低了公眾參與門檻,技術愛好者可通過平臺親手驗證算法性能。這種公共基礎設施的建立,或將像ImageNet推動AI發展一樣,成為具身智能時代的技術引擎——當機器人必須在真實世界中證明“確實聰明”,行業的創新效率與商業價值將迎來質的飛躍。