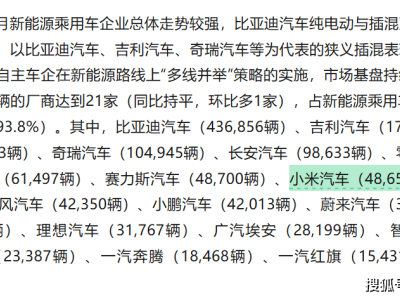
科技領域近日迎來一項引人矚目的進展——谷歌公司研發的新一代人工智能圖像生成模型Nano Banana 2,其早期預覽版本在正式發布前意外現身網絡。該模型在Media.ai平臺短暫上線后雖被緊急下架,但相關技術演示內容已在社交平臺引發廣泛討論,其展現的圖像處理能力被業內視為重要突破。
據技術分析,該模型的核心優勢體現在兩大技術維度。在物理邏輯模擬方面,其通過"圖生圖"技術實現了對動態場景的精準還原。例如在演示案例中,模型能根據輸入的靜態圖像,自動生成小球運動軌跡的完整動畫序列,這種涉及重力、慣性等物理參數的計算能力,顯著超越了現有同類產品的表現水平。
文本生成領域同樣取得關鍵進展。測試數據顯示,模型可基于自然語言指令,在白板、紙張等載體上生成排版規整的文本內容。與傳統模型生成的模糊文字不同,新系統能精確控制字體樣式、字號大小及字符間距,甚至支持多語言混合排版,為教育、設計等行業提供了高效的內容生成工具。
技術突破的背后,是模型對世界知識的深度理解能力。研發團隊透露,通過引入多模態學習框架,系統不僅掌握圖像像素間的關聯規則,更能理解物體間的物理關系、場景語義等復雜信息。這種認知升級使模型在執行"讓懸浮的杯子自然下落"等指令時,能自動生成符合物理規律的圖像序列,而非簡單的視覺拼接。
行業觀察者指出,該技術的實用價值已超越學術研究范疇。在媒體內容生產領域,編輯人員可借助模型快速完成圖片修復、色彩校正等基礎工作;廣告行業則能通過API接口實現營銷素材的批量生成,將單張海報的制作周期從數小時壓縮至分鐘級。某創意工作室負責人表示:"這種自動化工具將徹底改變視覺內容生產的工作流程,設計師可以更專注于創意構思而非重復勞動。"
盡管目前公開的僅為預覽版本,但技術社區已展開密集測試。開發者在GitHub平臺分享的測試報告顯示,模型在處理低分辨率圖像時,能通過多尺度特征融合技術實現4倍清晰度提升,且在人物面部特征還原等細節處理上表現優異。不過也有專家提醒,當前版本在復雜場景的光影模擬方面仍存在改進空間,完整版發布時可能引入新的神經網絡架構進行優化。